Illustrating the need for multi-tier approach on a very small application is good for simplicity and it helps getting the point across clearer, however, it is hardly justifiable. If you never felt the need for multiple tiers in your design, you are not going to feel that need after observing this small application in action. After all, you are an experienced developer and you can do all that this application does in half the time and using less than half the lines of code.
On the other hand, seeing the application evolve will possibly put things in perspective after we will attempt to pack months worth of iterative improvements into just a few 10 minutes increments. In fact, we will attempt to generalize the logic of the application so that it would become part of the larger theory as opposed to a single application example.
We find ourselves with an all too familiar task of getting some information from the database and displaying it on the screen. A task hardly worth an architectural eye, after all, you have done it hundreds of times before. In fact you are beginning to question whether you need enterprise level technology such as ASP.NET at all. Well, if you are 100% sure that you will never experience a load of more than 10 people at a time, and you will never have to upgrade or otherwise evolve your code we can stop right here. You are done and nothing else is necessary, however, zero upgrades or improvements simply do not exist in the world of IT.
Thinking of the task at hand
At this point we will follow a somewhat changed test-driven development methodology. To spare you the details of the approach let's just say that your test cases should come first (BEFORE the development) and every time you should write just enough code to pass the test. Adjusting it to our little application let's just write enough code to complete our little task that is currently at hand.
Shall we begin? We need some code that will open a connection to the database and will execute a stored procedure or an SQL statement, giving us something in return (a record set, a dataset, or an XML stream) we will then return it to the calling part of the code and let it deal with it however it sees fit.
So, what do we have so far? We have some spaghetti code that creates a connection to the database, right after that it executes the request and gets the data, it performs some HTML formatting and outputs it to the screen. Another job well done, and we didn't even need a code behind page, because we are sticking with basic scripting technology like classic ASP!
Figure 1:Basic ASP page
First requirement change!
It's changing time, we now have to support 200 simultaneous users on the page. Without database connection pooling we are eating up too many resources on SQL Server and our web server (not to mention that we cannot and should not create so many separate connection to the database, we should just reuse an existing open connection). To write our own database connection pooling would be a foolish task for such a small application and we are realizing that classic ASP is no longer enough. We need enterprise level. But not too worry, connection pooling is an automatic feature in ASP.NET that doesn't need to be coded for and so we are taking a few hours to convert the code from VB Script to C# and we are again good to go. We now support 200 simultaneous users.
Figure 2: ASPX page
The application keeps growing...(more pages)
We need 10 more pages that all go to the database. Not too worry, we copy-paste the code, make some minor adjustments to accommodate calling different stored procedures each time and again we are good to go.
The application keeps growing... (new Database server)
Great news! We are getting a more powerful database server, but the old one cannot be taken offline as it is still supporting other applications. We need to change the connection string everywhere. Global search and replace cannot be trusted, because you want to witness all updates and make sure that they are all correct. The problem is that you have to go through each of the pages. That just doesn't feel right, plus we tend to make mistakes on manual replaces, so we need a better solution.
What if we abstract the database opening code into its own class? This idea might just be crazy enough to work. A database connection class is created and is called from all other pages that require a database connection. The other changes in the name of the SQL server or user names or passwords will now take place in just 1 line of code!
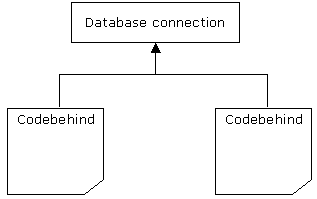
Figure 3:Database connection class
The project keeps expanding... (new developer and a new data source)
Well, our application is getting more popular by the hour, we need more pages, and we need them fast. So, we are getting a new developer. We are also getting more content in addition to the one stored in our database, and we are getting it through a data feed (for the sake of being modern, let's say that it's an RSS -XML based feed).
We now have a few problems: we are getting roughly the same type of data from 2 sources and we need a common "business" language between developers. Let's attack this one problem at a time.
Dealing with the feed:
Ideally the part of the code that deals with already retrieved data shouldn't care where the data is coming from, because it does not change the logic or the code. So we are now forced with a decision as to where to put the code that does the data accessing and retrieval and how do we pass that data further to the calling part of our application.
The obvious choice in the matter is that we need another class, a data-access class, and since it does nothing but access the data (from whatever source) we will place that in its own virtual layer (because there's no physical separation of classes, unless you want to place them in different folder).
Inventing a new data communication "language":
Now that we know where we are accessing the data, how do we make sure that the data being accessed, the data that another part of the project uses, and the data you will get from that other part of the project is all in the same format? How do we develop this new standard message format. The answer is of course, with classes!
We will create a class that represents the entities that we are returning. A good rule to follow from the database point of data access is that each row that you are returning should be encapsulated in a class. Basically most of the information coming in the row of data should be stored in a class. Keep in mind that once things get complicated you might have classes stored inside of other classes, but you should have no problems getting used to this, as it is very natural representation of the physical state of the object. For example if you have your morning paper be a class, and pages in that paper be their own classes, then your paper will hold a collection of page classes.
So now it's more or less taking shape of an enterprise level application. We have our connection classes, and our data access classes, a few modules that handle the business logic and they are all communicating using objects that are defined from the very beginning and represent your data entities. (By the way, if you need to return more than 1 object from the data access class, you should just return an array of these objects.)
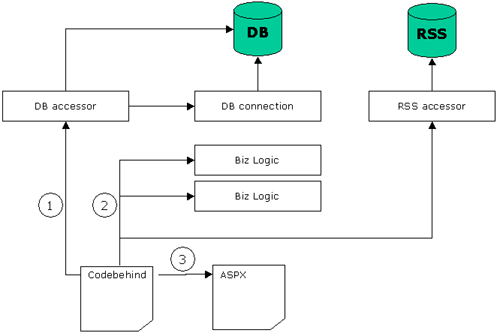
Figure 4: New layers
Presentation Layer or the continuing saga of multiple output channels...
Now that we have the collection of objects that we got from the database what do we do with them? How do we output them? The "natural way" for us would be to just do some string concatenation and spit it all out in the Response.Write statement. That works, what else can we possibly want from it? Well... our project owners decided to send a report (and by that we mean the html results from all that string concatenation and data representation) via email, and they want to FTP it to other development teams as well.
Copy-pasting any code doesn't really work, as we already had a chance to see, and the code that generates HTML is no different. So we need... you guessed it, another class. We need a class that takes an object or a collection of objects and produces HTML out of them, or whatever other format we need. We will call it a Utility type class and place it in the appropriate folder. We now have a presentation layer.
Ok, what just happened?
Well, let's quickly summarize what we have so far. Instead of old fashioned spaghetti code, which is a nightmare to maintain, we now have a 3-tier application. Let's take a look those tiers and the way they communicate with each other:
Data-Accessing tier (layer)
This layer consists of classes that are responsible for data retrieval from any data source (in our case we have 2: database, and RSS feed). Also as part of the layer we have a database connection class, that can be used by data accessing classes to establish a connection. By utilizing the same connection string all the time we are now taking advantage of .NET's built-in database connection pooling.
Another question that you might have is how do we convert one format of data (record of the dataset or XML) to our data holding classes (value objects). Well, there are 3 ways to do so:
- We can do that inside of the data accessing class itself.
- We can create another class that would convert data row or XML into value object.
- In case we are getting XML we can create a constructor in our value objects (the ones that will hold data and be passed between layers) and let them do their own parsing.
Business tier (layer)
We do not need to know much about how exactly the data is being handled here. All we need to know is that business rules are being applied here in order to alter the data in some way, or maybe we are adding some additional information or calculating additional fields that would be used in other layers.
The "message" will be received in a form of a value object and once fields of that value object will be changed or reinitialized another message in the form of the same value object will be send to another (calling) layer.
Presentation tier (layer)
This layer will initiate a request to a data-accessing layer asking for some information. Receive data in a form of an object, send it to the business layer for processing, get it back and send it for one of our Utility classes (still residing in the presentation layer) to get HTML out of this class to output to the screen or save in a file.
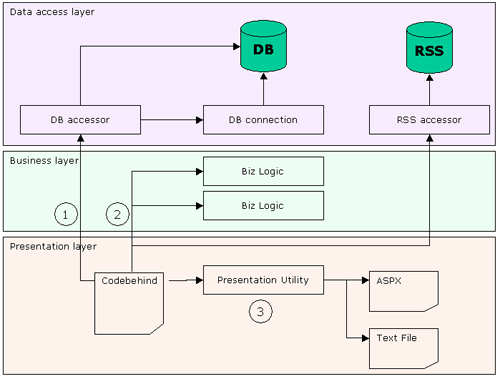
Figure 5:Application layers
Analyzing and improving (oh no! not another layer!)
Something doesn't feel right here. If we are getting some data from the database, what's stopping us from bypassing the business layer and passing this data straight to the presentation layer? The answer is NOTHING. The only person who controls the flow is the one writing the code at this very second, and even the same person can decide to bypass business logic when he or she sees fit. Hmm...
Another problem arises when we attempt to use a "support" type system, such as error logging. Where and when do we log the errors? Logging errors takes time, and if we place a lot of these logging statements, we will slow the application down and create an even bigger mess in the code, thus reducing the traceability of the application.
The answer at this point is not so easy. If you are looking for maximum flexibility for development, then you should allow access to the database layer and your error logging statements should be placed strategically throughout the entire body of code.
Manager classes
However, if you are looking to restrict the data flow in your application, then you need another layer of "manager" classes, which will be formed between the business logic layer and the presentation layer.
So what will happen in those manager classes? Let's start by saying that these classes are accessor classes, which means that they are grabbing information from data sources by means of the data-access layer. Except they provide more information in case something goes wrong, and they are also allowing inclusion of multiple supporting systems in the process.
So right now the presentation layer will initiate the call to the manager class to get some information. Manager class will create a request for this data to the data-accessing layer, once it gets the information it will decide whether it should be sent to a business logic layer, also it will report any anomalies it finds during this process and report it through the error logging systems and by means of its own fields and return values.
Are we there yet?
Right now we have an application that is designed for flexibility (you get data in a form of an object regardless of where it is coming from) and extensibility (your layers can be placed on separate machines therefore adding computing power, because they talk in objects and don't care how the other layers complete their tasks). We now have better traceability, because we can add supporting systems that will communicate errors and anomalies back to us. Basically speaking we now actually have a design of an application and not just a non-maintainable spaghetti code.
Keep in mind that the architecture proposed here is by no means a solution to all your problems, in fact in a lot of cases this would be an overkill. So keep the ideas that you like and ignore the rest. Happy programming!
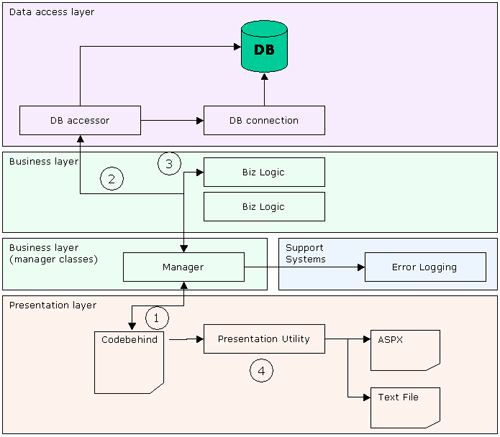
Figure 6:Complete picture