This article will explain how to:
-
Use a WebBrowser control in a Windows form
-
Navigate to a web site in the WebBrowser control
-
Access the HTML document in the WebBrowser control
-
Use the Document Object Model to find data in a table in the WebBrowser control
-
Create a web page from the data and show that web page in the WebBrowser control
Library of Congress Web Site
The sample for this article will get (scrape) data from a page of the United States Library of Congress (LOC) catalog data for bibliographic (book) data. To understand the sample, it will help to understand the web site pages being scraped. Go to Library of Congress Online Catalog and do a search. For example, in the search text enter:
ksub "c#" not music
And then select "Expert Search" for the search type. Then select one of the books in the results. If you do a search that results in just one book (such as an ISBN search), then you will see the book data directly without the list of books. In the first page of the book data, there will be tabs for "Brief Record", "Subjects/Content", "Full Record" and "MARC Tags". Click on the MARC Tags tab; you will then get a page that resembles:
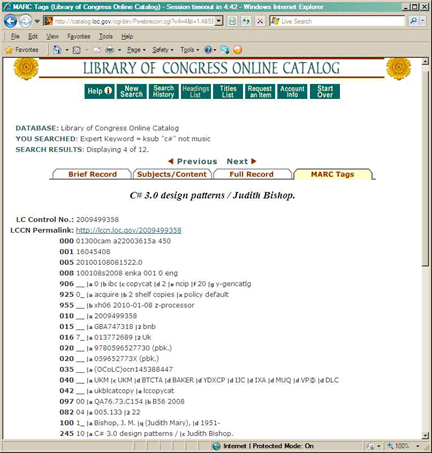
That is the data that this sample will scrape.
Note that we are getting the data from that web site for the purposes of this sample, but this is not the best way to get book data from the LOC using software; a better interface would be Z39.50. See the Library of Congress WWW/Z39.50 Gateway for more about Z39.50.
Overview
Finding data in a web page often is not easy. First we must find the data ourselves by viewing the page and the HTML, and then we must design a way for the program to find the data. Each web page is different but often the elements have an id or a name that can make things easier. We can use the HtmlElementCollection.GetElementsByName Method to easily find an element by id or by name. Sometimes we must find an element by iterating (going to each next element) the elements that precede it.
The Document Object Model is a standard way to represent HTML in programs. Dynamic HTML (DHTML) is similar. You can learn more about each in About the W3C Document Object Model.
HTML Classes in the Forms Namespace and in mshtml
The Forms Namespace has a few classes that help with the use of HTML in a WebBrowser control. The following table summarizes those classes.
| Class |
Description |
| HtmlDocument |
Represents all the HTML and other data of a HTML page, including the header and the body. |
| HtmlElement |
Each HTML tag is an element. |
| HtmlElementCollection |
A collection of elements, such as all the elements in a document. |
| HtmlElementErrorEventArgs |
Contains data about an error. |
| HtmlElementEventArgs |
Contains data for an event handler. |
| HtmlHistory |
A list of sites visited in the current session. |
| HtmlWindow |
Is the window that a document is in. |
| HtmlWindowCollection |
A collection of windows. |
Most classes that would be needed for scraping a page are not in the Forms Namespace. It is likely you will need more classes for the many things needed for processing a web page. There is a type library that can be used by managed code for HTML; to use it, add a reference for mshtml.dll (Microsoft HTML Object Library) and a using for the mshtml namespace.
The DomElement Property of the HtmlElement class can be used to get access to the mshtml objects for the element; similarly the HtmlDocument.DomDocument Property provides access to the mshtml objects for the document. Note that the objects in the Forms namespace are prefixed by "Html" (with lower-case "tml") and the objects in the mshtml namespace are prefixed by "HTML" (all upper-case characters).
Details of the Sample
For this sample, we begin by navigating the WebBrowser control to the LOC search page. When the user navigates to the MARC tags tab in the results, the user can select the option to scrape the data from the page.
The table we need happens to be preceded by a hidden INPUT element with a name of "RID", so we get the INPUT element using:
webBrowser1.Document.All.GetElementsByName("RID");
That returns a HtmlElementCollection, in which there should be one and only one element. The element collection in the sample is called ec, so the table is obtained using:
ec[0].NextSibling.DomElement as HTMLTable;
The return value of that is the table. We simply iterate through the rows of the table and process each cell. We ignore rows that do not have 2 cells and rows that do not have data in either or both cells.
After getting the data from the table, we create a new page for the purposes of formatting the data in the new page. This is done to show that we did in fact get the data and provides an example of building the HTML for a web page and how to navigate the WebBrowser control to the new page.