Introduction
Regular expressions is one of ways of search substrings in strings. It is carried out by means of viewing a string in searches of some pattern. A well-known example can be symbols "*" and "?", used in command line DOS. First of them replaces a zero or more any symbols, the second - one any symbol. So, use of a pattern of search of type "text?.*" will find files textf.txt, text1.asp and others similar, but will not find text.txt or text.htm.
Usually by means of regular expressions three actions are carried out:
- Stock-taking corresponding a pattern to a substring.
- Search and delivery to the user corresponding a pattern of substrings.
- Replacement corresponding a pattern substrings.
In practice are applied three types of machines of regular expressions.
- DFA (Deterministic Finite-state Automaton - the determined final automatic devices) machines work linearly on time as do not require recoils (and never check one symbol twice). They can guaranty find the longest string from possible. However, as DFA contains only a final condition, it cannot find the sample with the return reference and, because of absence of designs with obvious expansion, does not catch sub expressions. They are used, for example, in awk, egrep or lex.
- Traditional NFA-machines (NonDeterministic Finite-state Automaton - not determined final automatic devices) use "greedy" algorithm of recoil, checking all possible expansions of regular expression in the certain order and choosing the first suitable value. As traditional NFA designs the certain expansions of regular expression for search of conformity, it can search
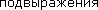 and backreferences. But because of recoils traditional NFA can check the same place some times. It as a result works more slowly. As traditional NFA accepts the first found conformity, it can and not find longest of ocurrences. Such mechanisms of regular expressions are used in Perl, Python, Emacs, Tcl and .Net.
and backreferences. But because of recoils traditional NFA can check the same place some times. It as a result works more slowly. As traditional NFA accepts the first found conformity, it can and not find longest of ocurrences. Such mechanisms of regular expressions are used in Perl, Python, Emacs, Tcl and .Net.
- POSIX NFA - machines are similar to traditional NFA-machines, except for "patience" - they continue search, yet will not find the longest conformity. Therefore POSIX NFA-machines more slowly traditional and consequently it is impossible to force POSIX NFA to prefer shorter conformity long. One of main advantages POSIX of the NFA-machine - presence of standard realization.
More often programmers use traditional NFA-machines as they are more exact, than DFA or POSIX NFA. Though time of their work grows in the worst case after an exhibitor, use of the samples reducing a level of ambiguity and limiting depth of search with return (backtracking), allows to operate their behavior, reducing time of search up to comprehensible values.
.NET Regular Expressions
The Regexp classes are allowed to use regular expressions in .NET. All classes are contained in the System.Text.RegularExpressions assembly, and you will have to reference the assembly at compile time in order to build your application. For example: csc /r:System.Text.RegularExpressions.dll foo.cs will build the foo.exe assembly, with a reference to the System.Text.RegularExpressions assembly.
There are only six classes and one delegate which it is necessary to overview:
- Capture: Contains the results of a single match
- CaptureCollection: A sequence of Capture's
- Group: The result of a single group capture, inherits from Capture
- Match: The result of a single expression match, inherits from Group
- MatchCollection: A sequence of Match's
- MatchEvaluator: A delegate for use during replacement operations
- Regex: An instance of a compiled regular expression
The Regex class also contains several static methods:
- Escape: Escapes regex metacharacters within a string
- IsMatch: Methods return a boolean result if the supplied regular expression matches within the string
- Match: Methods return Match instance
- Matches: Methods return a list of Match as a collection
- Replace: Methods that replace the matched regular expressions with replacement strings
- Split: Methods return an array of strings determined by the expression
- Unescape: Unescapes any escaped characters within a string
Example.
using System.Text.RegularExpressions;
using System;
namespace RegularExpressionsSample
{
class Program
{
static void Main(string[] args)
{
string regularExpression = "s[ia]mple";
string inputString = "Is it simple sample?";
Match m = Regex.Match(inputString, regularExpression);
Console.WriteLine("Match = " + m.ToString());
Console.WriteLine("Next match = " + m.NextMatch().ToString());
}
}
}
Output:
Match = simple
Next match = sample
Regular Expression Options:
Regular Expression Options can be used in the constructor for the Regex class.
- RegexOptions.None - Specifies that no options are set.
- RegexOptions.IgnoreCase - Specifies case-insensitive matching.
- RegexOptions.Multiline - Multiline mode. Changes the meaning of ^ and $ so they match at the beginning and end, respectively, of any line, and not just the beginning and end of the entire string.
- RegexOptions.Singleline - Specifies single-line mode. Changes the meaning of the dot (.) so it matches every character (instead of every character except \n).
- RegexOptions.ExplicitCapture - Specifies that the only valid captures are groups that are explicitly named or in the form (?<name>...).
- RegexOptions.IgnorePatternWhitespace - Eliminates unescaped white space from the pattern and enables comments marked with the hash sign (#).
- RegexOptions.Compiled - Specifies that the regular expression is compiled to an assembly. The regular expression will be faster to match but it takes more time to compile initially. This option (although tempting) should only be used when the expression will be used many times. e.g. in a foreach loop
- RegexOptions.ECMAScript - Enables ECMAScript-compliant behavior for the expression. This flag can be used only in conjunction with the IgnoreCase, Multiline, and Compiled flags. The use of this flag with any other flags results in an exception.
- RegexOptions.RightToLeft - Specifies that the search will be from right to left instead of from left to right.
Bases of syntax of regular expressions
I will not begin to try to write the full directory on all symbols used in patterns of regular expressions. For this purpose there is MSDN. Here we will result only the basic metasymbols. In double inverted commas the values which are given out by regular expressions, and in unary - syntax of regular expressions will be used further.
In C# metasymbols which you wish to use not as those and as actually symbols, should be covered by an escape-symbol \ as in C++ (in other languages can be differently, for example, in VB it is not necessary). That is, to find "[" , it is necessary to write '\['.The symbol \ means, that the symbol following it is special symbol, a constant and so on. For example, 'n' means the letter "n." '\n' means a symbol of a new line. The sequence '\\' corresponds "\", and '\(' corresponds "(".
Classes of symbols (Character class)
Using square brackets, it is possible to specify group of symbols (it name a class of symbols) for search. For example, the design 'b[ai]rge' would correspond to words "barge" and "birge", i.e. the words beginning with "b" which follow "a" or "i", and coming to an end on "rga". Probably and the return, that is, it is possible to specify symbols which should not contain in found substring. So, '[^1-6]' finds all symbols, except for figures from 1 up to 6. It is necessary to mention, that inside of a class of symbols '\b' designates a symbol backspace (deletings).
Quantifiers
If it is not known, how many signs should contain required substring, it is possible to use special symbols, called by an odd word quantifiers. For example, it is possible to write "hel+o", that will mean a word beginning with "he", with following for it one or the several "l", and coming to an end on "o". It is necessary to understand, that quantifier concerns to previous expression, instead of a separate symbol.
| Symbol |
Overview |
| * |
Corresponds 0 or more occurrences of previous expression.
For example, 'zo*' corresponds "z" and "zoo". |
| + |
Corresponds 1 or more previous expressions.
For example, 'zo+' corresponds "zo" and "zoo", but not "z". |
| ? |
Corresponds 0 or 1 previous expressions.
For example, 'do(es)?' corresponds "do" in "do" or "does". |
| *? |
Corresponds 0 or more previous expressions as few characters as possible.
For example, 'dog*?' corresponds "do" in "do" or "does" |
| +? |
Corresponds 1 or more previous expressions as few characters as possible.
For example, 'dog+?' corresponds "dog" in "dog" or "dogger". |
| {n} |
n - the non-negative whole. Corresponds to exact quantity of occurrences.
For example, 'o{2}' will not find "o" in "Bob", but will find two "o" in "food". |
| {n,} |
n - the non-negative whole. Corresponds to the occurrence repeated not less n of time.
For example, 'o{2,}' does not find "o" in "Bob", but finds all "o" in "foooood".
'o{1,}' it is equivalent 'o+'.
'o{0,}' it is equivalent 'o*'. |
| {n,m} |
m and n - non-negative integers, where n <= m. There corresponds a minimum n and a maximum m occurrences.
For example, 'o{1,3}' finds three first "o" in "fooooood".
'o{0,1}' it is equivalent 'o?'.
The blank space between a comma and figures is inadmissible. |
| | |
When between two characters or groups, matches one or the other (this is called an alternating operation, because it chooses among two alternatives). |
Table 1. Quantifiers.
The important feature of quantifiers '*' and '+' is their greed. They find everything, that can - instead of that is necessary.
Example.
| |
Source string - "hello out there, how are you"
Regular expression - 'h.*o'
It means to search 'h' which any symbols which follows 'o' follow some. In a kind, probably, was available "hello", but it will be found "hello out there, how are you" - because of greed of the regular expression looking not first, but last "o". To cure quantifier of greed it is possible, having added '?'. That is,
Source string - "hello out there, how are you"
Regular expression - 'h.*?o'
will find "hello", as it was necessary, as searches 'h' which any symbols follow some, up to the first met 'o'. |
The ends and the beginnings of strings
Check has begun the ends or the end of a line is made by means of metasymbols ^ and $. For example, '^thing' corresponds to a line beginning with "thing". 'thing$' corresponds to a line which is coming to an end on "thing". These symbols work only at the included option 's'. At the switched off option 's' there is only an end and the beginning of the text. There is also a symbol \z, an exact end of a line.
Border of a word
For the task of borders of a word metasymbols '\b' and '\B' are used.
Regular expression 'out' corresponds not only "out" in "speak out loud", but also "out" in "please do not shout at me". To avoid it, it is possible to anticipate the sample a marker of border of a word.
With the expression '\bout' it will be found only "out" in the beginning of a word. It is necessary, that inside of a class of symbols '\b' designates a symbol backspace (deletings).
Other special characters
In the table below I have displayed other special symbols:
| Symbol |
Overview |
| \a |
Matches a bell (alarm). |
| \b |
Matches a backspace if in a [] character class; otherwise, see above. |
| \t |
Matches a tab. |
| \r |
Matches a carriage return. |
| \v |
Matches a vertical tab. |
| \f |
Matches a form feed. |
| \n |
Matches a new line. |
| \e |
Matches an escape. |
| \w |
Matches a character(a-z, A-z, 0-9 and underscore). |
| \W |
Matches any character that is not a letter. |
| \s |
Matches any white spaces(space or tab). |
| \S |
Matches any character that is not white space. |
| \d |
Matches a digit(0-9). |
| \D |
Matches any character that is not a digit. |
| . |
Matches any character, except the end of line or the end of text. |
| $ |
Matches the end of the string or line. |
Table 2. Other special symbols
Grouping and Backreferences
You can group patterns by placing them in parenthesis. You can give a name to the group as well. Here are some of the grouping constructs you'll be using:
| Construction |
Overview |
| () |
Defines a simple group. |
| (?<name>) |
Group named "name" |
| (?i:) |
Igonre case when matching within the group |
| \n |
Matches a previous group(group #n)
For example, (\w)\1 finds doubled word characters. |
| \k<name> |
Matches a previous group with the specified name.
For example, (?<char>\w)\k<char> finds doubled word characters. The expression (?<43>\w)\43 does the same. You can use single quotes instead of angle brackets; for example, \k'char'. |
Table 3. Grouping patterns
Groups that don't have a name, have a number.
Example.
using System.Text.RegularExpressions;
using System;
namespace RegularExpressionsSample
{
class Program
{
static void Main(string[] args)
{
// Should match everything except the last two.
string regularExpression = @"\$(\d+)\.(\d\d)";
string inputString = "$1.57 $316.15 $19.30 $0.30 $0.00 $41.10 $5.1 $.5";
for (Match m = Regex.Match(inputString, regularExpression); m.Success; m = m.NextMatch())
{
GroupCollection gc = m.Groups;
Console.WriteLine("The number of captures: " + gc.Count);
// Group 0 is the entire matched string itself
// while Group 1 is the first group to be captured.
for (int i = 0; i < gc.Count; i++)
{
Group g = gc[i];
Console.WriteLine(g.Value);
}
}
}
}
}
Output:
The number of captures: 3
$1.57
1
57
The number of captures: 3
$316.15
316
15
The number of captures: 3
$19.30
19
30
The number of captures: 3
$0.30
0
30
The number of captures: 3
$0.00
0
00
The number of captures: 3
$41.10
41
10
Replacement
Substitutions are allowed only within a replacement pattern. For similar functionality within a regular expression, use a backreference such as \1.
Character escapes and substitutions are the only special constructs recognized in a replacement pattern. All other syntactic constructs are allowed in regular expressions only and not recognized in replacement patterns. For example, the replacement pattern 'a*${test}b' inserts the string "a*" followed by the substring matched by the "test" capturing group, if any, followed by the string "b". The * character is not recognized as a metacharacter within a replacement pattern. Similarly, $-patterns are not recognized within a regular expression matching pattern. Within a regular expression, $ denotes the end of the string. Other examples are: '$123' substitutes the last substring matched by group number 123 (decimal), and ${name} substitutes the last substring matched by a (?<name>) group.
Example.
Formatting string with replace method.
using System.Text.RegularExpressions;
using System;
namespace RegularExpressionsSample
{
class Program
{
static void Main(string[] args)
{
string regularExpression = @"(\s*)Dim\s+(\w+)\s+As\s+(\w+)";
string inputString = "Dim abc As Integer";
string replacement = "$1$3 $2;";
Console.WriteLine(Regex.Replace(inputString, regularExpression, replacement));
}
}
}
Output:
Integer abc;
Lookaround
There are two directions of lookaround - lookahead and lookbehind - and two flavors of each direction - positive assertion and negative assertion. The syntax for each is:
- (?=...) - Positive lookahead
- (?!...) - Negative lookahead
- (?<=...) - Positive lookbehind
- (?<!...) - Negative lookbehind
Understanding look(ahead|behind) requires an understanding of the difference between matching text and matching position. To help with this understanding I should state first that lookaround assertions are non-consuming. To see what I mean, let's look at the following simple example.
regularExpression = "stop";
inputString = "stopping";
When the above pattern is applied to the text the "context" of the parser sits at a position in the text between the "s" and the "i" in the word stopping. This is because the regular expression parser bumps along the string as it gets a match, like so:
- Start - ^stopping
- Match "s" - ^topping
- Match "t" - s^opping
- Match "o" - st^pping
- Match "p" - sto^ping
Once the parser has moved beyond a position there is no way to reverse up and re-attempt a match. To understand where this causes difficulty, consider this, what if you needed to match the word "stop" but only when it was contained in the word "stopped" and not any other possible combination such as "stopper". With lookahead you can simply assert that condition like so: (?=stopped\b)stop
This works because, with lookaround, the parser is not bumped along the string. This can be especially useful for finding a position in a document by combining a lookahead assertion with a lookbehind assertion. To demonstrate, let's consider that we need to match the string "stop" when it was contained within the string "estopped" but not "astopped". To do this you can do a negative, lookbehind assertion on "a" and a positive lookahead assertion on "stopped", like this: (?<!a)(?=stopped\b)stop
In other words you are matching a position at which to start matching text. The above pattern would set the parser at the following position in the string "estopped"
Start - e^stopped
Match "s" - e^topped
Match "t" - es^opped
Match "o" - est^pped
Match "p" - esto^ped
Example.
Example of using lookaround would be to validate "special" password conditions such as: "Password must be between 8 and 20 characters, must contain at least 2 letter characters and at least 2 digit characters. It can only contain either letter or digit characters."
For such a password constraint, the following expression would probably do quite nicely: ^(?=.*?\d.*?\d)(?=.*?\w.*?\w)[\d\w]{8,20}$
using System.Text.RegularExpressions;
using System;
namespace RegularExpressionsSample
{
class Program
{
static void Main(string[] args)
{
string regularExpression = @"^(?=.*?\d.*?\d)(?=.*?\w.*?\w)[\d\w]{8,20}$";
Console.WriteLine("Please input password for check:");
string inputString = Console.ReadLine();
if (inputString != "" && Regex.IsMatch(inputString, regularExpression))
{
Console.WriteLine("It's correct security password");
}
else
{
Console.WriteLine("It's incorrect password.");
}
Console.Read();
}
}
}
Output:
Please input password for check:
abc4D5678
It's correct security password
The most actual regular expression patterns
| Pattern |
Description |
| ^[\w-\.]+@([\w-]+\.)+[\w-]{2,4}$ |
This expression matches email addresses, and checks that they are of the proper form. It checks to ensure the top level domain is between 2 and 4 characters long. |
| ^(\(?\+?[0-9]*\)?)?[0-9_\- \(\)]*$ |
A regular expression to match phone numbers, allowing for an international dialing code at the start and hyphenation and spaces that are sometimes entered. |
| ^\d{1,2}\/\d{1,2}\/\d{4}$ |
This regular expressions matches dates of the form XX/XX/YYYY where XX can be 1 or 2 digits long and YYYY is always 4 digits long. |
| ^([0-1][0-9]|[2][0-3]):([0-5][0-9])$ |
This regular expressions matches time in the format of HH:MM
|
| \b(([01]?\d?\d|2[0-4]\d|25[0-5])\.){3}([01]?\d?\d|2[0-4]\d|25[0-5])\b |
This regular expressions matches Decimal IPs.
|
| ^\d{5}$|^\d{5}-\d{4}$ |
This regular expression will match either a 5 digit ZIP code or a ZIP+4 code formatted as 5 digits, a hyphen, and another 4 digits. |
| ^\d{3}-\d{2}-\d{4}$ |
This regular expression will match a hyphen-separated Social Security Number (SSN) in the format NNN-NN-NNNN. |
| ^((4\d{3})|(5[1-5]\d{2})|(6011))-?\d{4}-?\d{4}-?\d{4}|3[4,7]\d{13}$ |
Matches major credit cards including: Visa (length 16, prefix 4), Mastercard (length 16, prefix 51-55), Discover (length 16, prefix 6011), American Express (length 15, prefix 34 or 37). All 16 digit formats accept optional hyphens (-) between each group of four digits. |
(http|https|ftp)\://[a-zA-Z0-9\-\.]+\.[a-zA-Z]{2,3}(:[a-zA-Z0-9]*)?/?([a-zA-Z
0-9\-\._\?\,\'/\\\+&%\$#\=~])* |
This regular expression will match some URL. |
The conclusion
It only brief conducting in regular expressions and their use. If you wish to understand better it, try to be trained in creation of regular expressions independently. Practice shows, that analysis of another's regular expressions is practically useless, to read them it is almost impossible. However it is better to learn to use them is often simplifies a life.