Introduction
This article describes three approaches to parsing the sentences from a body of text; three approaches are shown as a means of describing the pros and cons for performing this task using each different approach. The demonstration application also describes an approach to generating sentence count, word count, and character count statistics on a body of text.
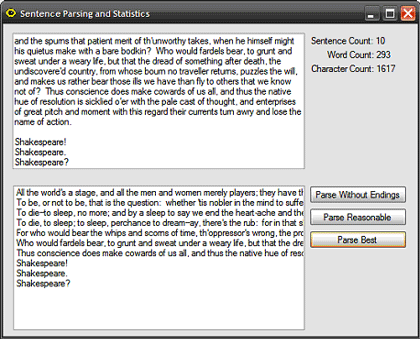
Figure 1: The test application running
The three approaches to parsing out the sentences from the body of text include:
- Parse Reasonable: An approach based on splitting the text using typical sentence terminations where the sentence termination is retained.
- Parse Best: An approach based on the use of splitting the text based upon the use of a regular expression and where the sentence termination is retained, and
- Parse Without Endings: An approach to splitting the text using typically sentence terminations where the terminations are not retained as part of the sentence.
The demonstration application contains some default text in a text box control; three buttons used to parse the text using one of the three approaches mentioned, and three label controls used to display the summary statistics generated on the body of text. Once the application is run, clicking on any of the three buttons will result in the display of each of the parsed sentences within the list box control at the bottom of the form, and will result in the display of the summary statistics using the three labels in the upper right hand side of the form.
Getting Started:
In order to get started, unzip the included project and open the solution in the Visual Studio 2008 environment. In the solution explorer, you should note these files (Figure 2):
Figure 2: Solution Explorer
As you can see from Figure 2; there is a single Win Forms project containing a single form. All code required of this application is included in this form's code.
The Main Form (Form1.cs).
The main form of the application, Form1, contains all of the code necessary. The form contains default text within a text box control; the three buttons are used to execute each of the three functions used to parse the body of text into a collection of strings; one per sentence. You may replace, remove, or add to the text contained in the text box control to run the methods against your own text. Three label controls are used to display summary statistics (sentence, word, and character counts) on the text contained in the text box control. These summary statistics are updated each time the text is parsed into sentences.
If you'd care to open the code view up in the IDE you will see that the code file begins with the following library imports:
using System;
using System.Collections;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Text;
using System.Windows.Forms;
using System.Text.RegularExpressions;
Note that the defaults have been altered and now include the reference to the regular expressions library.
Following the imports, the namespace, class, and constructor are defined:
namespace SentenceParser
{
/// <summary>
/// Demonstrate three approaches to parsing
/// a body of text into sentences and also
/// demonstrates an approach to building
/// statistics on the text to include the
/// number of sentences, the number of
/// words and the number of characters
/// used in the text.
/// </summary>
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
Next up is a region entitled, "Best Sentence Parser"; this region contains a function entitled, "SplitSentences" which accepts a string as an argument. This method tends to yield the best results in terms of parsing sentences but may issue inaccurate values if the text contains errors. The region also contains a button click event handler used to evoke the SplitSentences function.
The code is annotated and reading through the notes will explain what is going on within the function.
#region Best Sentence Parser
/// <summary>
/// This is generally the most accurate approach to
/// parsing a body of text into sentences to include
/// the sentence's termination (e.g., the period,
/// question mark, etc). This approach will handle
/// duplicate sentences with different terminations.
/// </summary>
/// <param name="sSourceText"></param>
/// <returns></returns>
private ArrayList SplitSentences(string sSourceText)
{
// create a local string variable
// set to contain the string passed it
string sTemp = sSourceText;
// create the array list that will
// be used to hold the sentences
ArrayList al = new ArrayList();
// split the sentences with a regular expression
string[] splitSentences = Regex.Split(sTemp, @"(?<=['""A-Za-z0-9][\.\!\?])\s+(?=[A-Z])");
// loop the sentences
for (int i = 0; i < splitSentences.Length; i++)
{
// clean up the sentence one more time, trim it,
// and add it to the array list
string sSingleSentence = splitSentences[i].Replace(Environment.NewLine, string.Empty);
al.Add(sSingleSentence.Trim());
}
// update the statistics displayed on the text
// characters
lblCharCount.Text = "Character Count: " + GenerateCharacterCount(sTemp).ToString();
// sentences
lblSentenceCount.Text = "Sentence Count: " + GenerateSentenceCount(splitSentences).ToString();
// words
lblWordCount.Text = "Word Count: " + GenerateWordCount(al).ToString();
// return the arraylist with
// all sentences added
return al;
}
/// <summary>
/// Calls the SplitSentences (best approach) method
/// to split the text into sentences and displays
/// the results in a list box
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void btnParseBest_Click(object sender, EventArgs e)
{
lstSentences.Items.Clear();
ArrayList al = SplitSentences(txtParagraphs.Text);
for (int i = 0; i < al.Count; i++)
//populate a list box
lstSentences.Items.Add(al[i].ToString());
}
#endregion
Next up is a region entitled, "Reasonable Sentence Parser"; this region contains a function entitled, "ReasonableParser" which accepts a string as an argument. This method tends to yield fair results in terms of parsing sentences but does not apply the proper sentence terminations if the input string contains duplicate sentence with different terminations. This issue could be resolved by use of a recursive function to continue to move through each instance of the duplicate sentence however it is less work to use the method indicated in the previous code region. The region also contains a button click event handler used to evoke the ReasonableParser function.
The code is annotated and reading through the notes will explain what is going on within the function.
#region Reasonable Sentence Parser
/// <summary>
/// This does a fair job of parsing the sentences
/// unless there are duplicate sentences;
/// you'd have to resort to recursion in order
/// to get through the issue of multiple duplicate sentences.
/// </summary>
/// <param name="sTextToParse"></param>
/// <returns></returns>
private ArrayList ReasonableParser(string sTextToParse)
{
ArrayList al = new ArrayList();
// get a string from the contents of a textbox
string sTemp = sTextToParse;
sTemp = sTemp.Replace(Environment.NewLine, " ");
// split the string using sentence terminations
char[] arrSplitChars = { '.', '?', '!' };
// things that end a sentence
//do the split
string[] splitSentences = sTemp.Split(arrSplitChars,StringSplitOptions.RemoveEmptyEntries);
// loop the array of splitSentences
for (int i = 0; i < splitSentences.Length; i++)
{
// find the position of each sentence in the
// original paragraph and get its termination ('.', '?', '!')
int pos = sTemp.IndexOf(splitSentences[i].ToString());
char[] arrChars = sTemp.Trim().ToCharArray();
char c = arrChars[pos + splitSentences[i].Length];
// since this approach looks only for the first instance
// of the string, it does not handle duplicate sentences
// with different terminations. You could expand this
// approach to search for later instances of the same
// string to get the proper termination but the previous
// method of using the regular expression to split the
// string is reliable and less bothersome.
// add the sentences termination to the end of the sentence
al.Add(splitSentences[i].ToString().Trim() + c.ToString());
}
// Update the show of statistics
lblCharCount.Text = "Character Count: " + GenerateCharacterCount(sTemp).ToString();
lblSentenceCount.Text = "Sentence Count: " +GenerateSentenceCount(splitSentences).ToString();
lblWordCount.Text = "Word Count: " +GenerateWordCount(al).ToString();
return al;
}
/// <summary>
/// Calls the ReasonableParser method and
/// displays the results
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void btnParseReasonable_Click(object sender, EventArgs e)
{
lstSentences.Items.Clear();
ArrayList al = ReasonableParser(txtParagraphs.Text);
for (int i = 0; i < al.Count; i++)
{
lstSentences.Items.Add(al[i].ToString());
}
}
#endregion
Next up is a region entitled, "Parse Withou Sentence Terminations"; this region contains a function entitled, "IDontCareHowItEndsParser" which accepts a string as an argument. This method tends to yield good results in terms of parsing sentences but does not add the termination to the parsed sentences; this is a good approach to use if you don't care what termination is used at the end of the sentence. The region also contains a button click event handler used to evoke the IDontCareHowItEndsParser function.
The code is annotated and reading through the notes will explain what is going on within the function.
#region Parse Without Sentence Terminations
/// <summary>
/// If you don't care about retaining the sentence
/// terminations, this approach works fine. This
/// will return an array list containing all of the
/// sentences contained in the input string but
/// each sentence will be stripped of its termination.
/// </summary>
/// <param name="sTextToParse"></param>
/// <returns></returns>
private ArrayList IDontCareHowItEndsParser(string sTextToParse)
{
string sTemp = sTextToParse;
sTemp = sTemp.Replace(Environment.NewLine, " ");
// split the string using sentence terminations
char[] arrSplitChars = { '.', '?', '!' }; // things that end a
sentence
//do the split
string[] splitSentences = sTemp.Split(arrSplitChars,StringSplitOptions.RemoveEmptyEntries);
ArrayList al = new ArrayList();
for (int i = 0; i < splitSentences.Length; i++)
{
splitSentences[i] = splitSentences[i].ToString().Trim();
al.Add(splitSentences[i].ToString());
}
// show statistics
lblCharCount.Text = "Character Count: " +GenerateCharacterCount(sTemp).ToString();
lblSentenceCount.Text = "Sentence Count: " + GenerateSentenceCount(splitSentences).ToString();
lblWordCount.Text = "Word Count: " + GenerateWordCount(al).ToString();
return al;
}
/// <summary>
/// Calls the IDontCareHowItEndsParser and displays
/// the results
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void btnParseNoEnding_Click(object sender, EventArgs e)
{
lstSentences.Items.Clear();
ArrayList al = IDontCareHowItEndsParser(txtParagraphs.Text);
for (int i = 0; i < al.Count; i++)
{
lstSentences.Items.Add(al[i].ToString());
}
}
#endregion
The final region is entitled, "Generate Statistics". This region contains three functions which return the character count, word count, and sentence counts for a body of text. Again, this section is annotated; read through the annotation to get a description of how each function works.
#region Generate Statistics
/// <summary>
/// Generate the total character count for
/// the entire body of text as converted to
/// one string
/// </summary>
/// <param name="allText"></param>
/// <returns>int count of all characters</returns>
public int GenerateCharacterCount(string allText)
{
int rtn = 0;
// clean up the string by
// removing newlines and by trimming
// both ends
string sTemp = allText;
sTemp = sTemp.Replace(Environment.NewLine, string.Empty);
sTemp = sTemp.Trim();
// split the string into sentences
// using a regular expression
string[] splitSentences =Regex.Split(sTemp, @"(?<=['""A-Za-z0-9][\.\!\?])\s+(?=[A-Z])");
// loop through the sentences to get character counts
for(int cnt=0; cnt<splitSentences.Length; cnt++)
{
// get the current sentence
string sSentence = splitSentences[cnt].ToString();
// trim it
sSentence = sSentence.Trim();
// convert it to a character array
char[] sentence = sSentence.ToCharArray();
// test each character and
// add it to the return value
// if it passes
for (int i = 0; i < sentence.Length; i++)
{
// make sure it is a letter, number,
// punctuation or whitespace before
// adding it to the tally
if (char.IsLetterOrDigit(sentence[i]) ||char.IsPunctuation(sentence[i]) || char.IsWhiteSpace(sentence[i]))
rtn += 1;
}
}
// return the final tally
return rtn;
}
/// <summary>
/// Generate a count of all words contained in the text
/// passed into to this function is looking for
/// an array list as an argument; the array list contains
/// one entry for each sentence contained in the
/// text of interest.
/// </summary>
/// <param name="allSentences"></param>
/// <returns>int count of all words</returns>
public int GenerateWordCount(ArrayList allSentences)
{
// declare a return value
int rtn = 0;
// iterate through the entire list
// of sentences
foreach (string sSentence in allSentences)
{
// define an empty space as the split
// character
char[] arrSplitChars = {' '};
// create a string array and populate
// it with a split on the current sentence;
// use the string split option to remove
// empty entries so that empty sentences do not
// make it into the word count.
string[] arrWords = sSentence.Split(arrSplitChars,
StringSplitOptions.RemoveEmptyEntries);
rtn += arrWords.Length;
}
// return the final word count
return rtn;
}
/// <summary>
/// Return a count of all of the sentences contained in the
/// text examined; this method is looking for a string
/// array containing all of the sentences; it just
/// returns a count for the string array.
/// </summary>
/// <param name="allSentences"></param>
/// <returns></returns>
public int GenerateSentenceCount(string[] allSentences)
{
// create a return value
int rtn = 0;
// set the return value to
// the length of the sentences array
rtn = allSentences.Length;
// return the count
return rtn;
}
#endregion
Summary
This article is intended to describe several approaches for parsing the sentences out of a body of text. Further, the article describes three functions which may be used to generate summary statistics on a body of text. There are of course other ways that may be used to do each of these things. In general, the best approach to parsing out the sentences appears to be through the use of a regular expression. Modifications to the regular expression may yield different results which might work better with the sort of text you are working with; however, I have found that this approach works well with even complicated bodies of text so long as the text is properly formatted into proper sentences.